

Do the vaccine pushers even KNOW that the CDC is hiding VAERS death reports?
And a rant about using Twitter Spaces for debates on technical topics

Summary:
VAERS follow up reports filed without referencing the initial report are deleted periodically by the CDC, because they are considered duplicates
Organizations like MedAlerts and VAERSAnalysis track and publish deleted report IDs
The CDC WONDER search system only shows original report outcomes, which hides information included in the followup reports from the public
Even VAERS death reports can sometimes be hidden when they're updates to earlier hospitalization reports
Follow-up reports typically indicate worsening conditions, not improvements
The lack of transparency in this process makes it impossible to properly analyze adverse event progression, particularly for conditions like myocarditis.
Independent researchers need the CDC to publish mappings between original and updated report IDs to do rigorous safety monitoring
These issues prove especially difficult to discuss on platforms like Twitter Spaces, where the synchronous audio format prevents proper examination of technical details and data
During our Twitter back and forth, The Real Truther wrote this shocking reply and even put it in quotes!
As usual, Truther refuses to answer questions raised by other people (you know, the kind of questions which showcase the ignorance of the vaccine pushers) so that he can pretend that he is the “winner” of every debate.
An important point that people rarely notice - Truther almost never answers legitimate questions about VAERS because he doesn't really understand many parts of it. After that he also unilaterally declares he has won every single debate LMAO.
But you can read the full conversation around that tweet I linked and notice that he has dodged answering the main question - whether or not he supports the CDC publishing a mapping between deleted and original VAERS reports.
Anyone with some basic common sense will see that because of the precautionary principle in medicine, Truther's approach to vaccine debates is an inversion of real world expectations. A vaccine is a prophylactic administered to healthy people. Every single vaccine related death report must be investigated thoroughly.
By the way, this seems to be a pretty fundamental difference between the philosophies of the vaccine pushers and the vaccine skeptics. I personally think the CDC has fallen far short of people's expectations. I think most of the vaccine pushers would say the CDC has done an amazing job!
For example, even on the rare occasion that the CDC does publish something related to vaccine injuries the data analysis is either laughably bad or they just selectively hide some data to make the vaccine seem safer than it is.
In fact I now predict that the CDC will never publish a comprehensive paper on vaccine death reports based on VAERS and v-safe, including a rigorous and complete analysis of the writeups, because a lot of clearly healthy people died after taking the COVID19 vaccine. This is why I keep pointing out that the current state of vaccine pharmacovigilance is third rate.The problem with Spaces as a debate platform
I need to digress a little here to make my next set of points.
Spaces is a very poor platform for having debates on technical topics.
For one it isn’t actually easy to skim the transcript of a Spaces debate. With all the advancement in AI, you would think Twitter would have enabled this as a Premium feature1. Even if Truther’s “debates” are really as amazing as he thinks they are, I have much better things to do with my time than listen to long rants about anti-vaxxers with an unpredictable signal to noise ratio.
Second, it is not even straightforward for non-debate participants to download the debate audio recording without writing Python code2.
Third, the lack of video input means a lot of stuff cannot even be properly discussed on Twitter Spaces. I will focus on the third one because it is very relevant to this particular article.
Fourth, the synchronous nature of audio debates makes it much harder for people to go and do some research3 and come back with counterarguments like you can do with text.
As an example, here is Prof Jeffrey Morris refusing to answer my basic question for three days in a row. He still hasn’t answered, so now it is five days in a row.
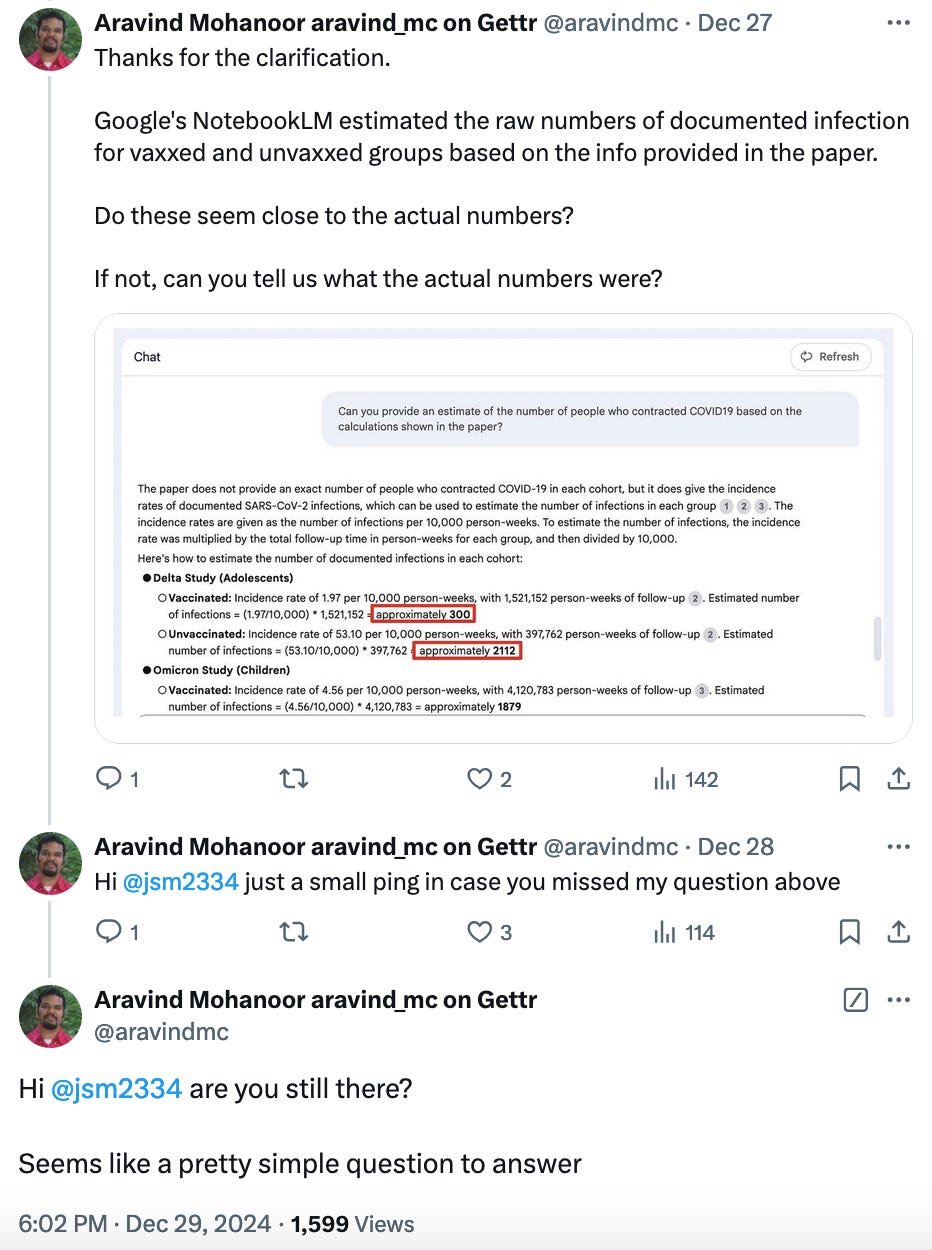
But he did make some time to perform his self-appointed role as the pro-Pharma reply guy under VAERS related tweets from high follower accounts. This was after I asked my question, so we know he hasn’t taken a break from Twitter entirely.

By the way, this reply from Prof Morris is a good example of deflecting attention from the crux of the argument.
Speaking of deflecting attention from the crux of the argument, someone called Henjin came to Jeff Morris’s rescue by answering my question with this comically bizarre response.

What Henjin has written makes no sense in this context.
I will explain why in my next article which will also summarize why the NIH RECOVER consortium dataset needs a serious audit. Things are probably even worse than I initially thought.
I am still hoping that Prof Jeff Morris will reply to my specific question before I write my next article because
a) he is the author of the paper and should, in theory, know the underlying data better than anyone else
b) when he needs4 assists from Twitter anons like Henjin, it only makes people even more suspicious about the underlying data and I hope he realizes that
Now, coming back to the synchronous nature of audio debates versus asynchronous nature of text debates, you can see that someone like Jeff Morris cannot just ramble and rant and run out the clock in a text debate, like people sometimes do in an audio debate.
As a quick aside this is why I don't think we can conclude anything based on the fact that Peter Hotez or Paul Offit will not do a debate with RFK Jr on a podcast like Joe Rogan.
The synchronous audio/video format is not well suited for technical debates, and they have a valid argument when they say they cannot debate someone like RFK Jr who has training as a lawyer because
a) his lawyer training taught RFK Jr to use words much more judiciously than an untrained domain-expert debate-opponent, causing the domain expert to make casual but regrettable mistakes because of the need to respond quickly
b) scientists who are genuine peers can never resolve ANYTHING via audio debates in my opinion. They need to still go back to the drawing board and work things out for themselves to confirm what they heard the other person say. (Some people might say I just defined peer review. The problem is only an utterly broken peer review process could have allowed the CDC v-safe Lancet paper to get published)How the CDC hides VAERS death reports
So now we will get into the nitty-gritty of how this process unfolds. You can probably explain all this over audio, but using visuals will actually make it much easier to understand.
1 The CDC publishes or updates three VAERS CSV files each month (six if you count foreign VAERS reports). During COVID19, because of the extremely high volume, they had to switch to publishing it weekly. Now they are back to publishing monthly.
2 Some folks who are tracking VAERS (such as MedAlerts and VAERSAnalysis) download these CSV files as soon as they are published.
3 Each report inside the CSV file has a VAERS ID, usually representing a single patient. Based on this, the folks tracking VAERS will keep track of all the VAERS IDs which have been published historically.
4 On a future date, the CDC sometimes removes a previously published VAERS ID from their CSV file. Because the folks tracking VAERS already have the full list of published VAERS IDs, they can now calculate which IDs were removed from the CSV file.
Here is an example of what this looks like when you use VAERS Wayback machine on MedAlerts

This is what we refer to as a “deleted” VAERS report.
VAERSAnalysis created a SQL script which allows people to download the full list of deleted VAERS IDs from Jan 2021.
You can click on the link5 to download the CSV file with a list of deleted reports.
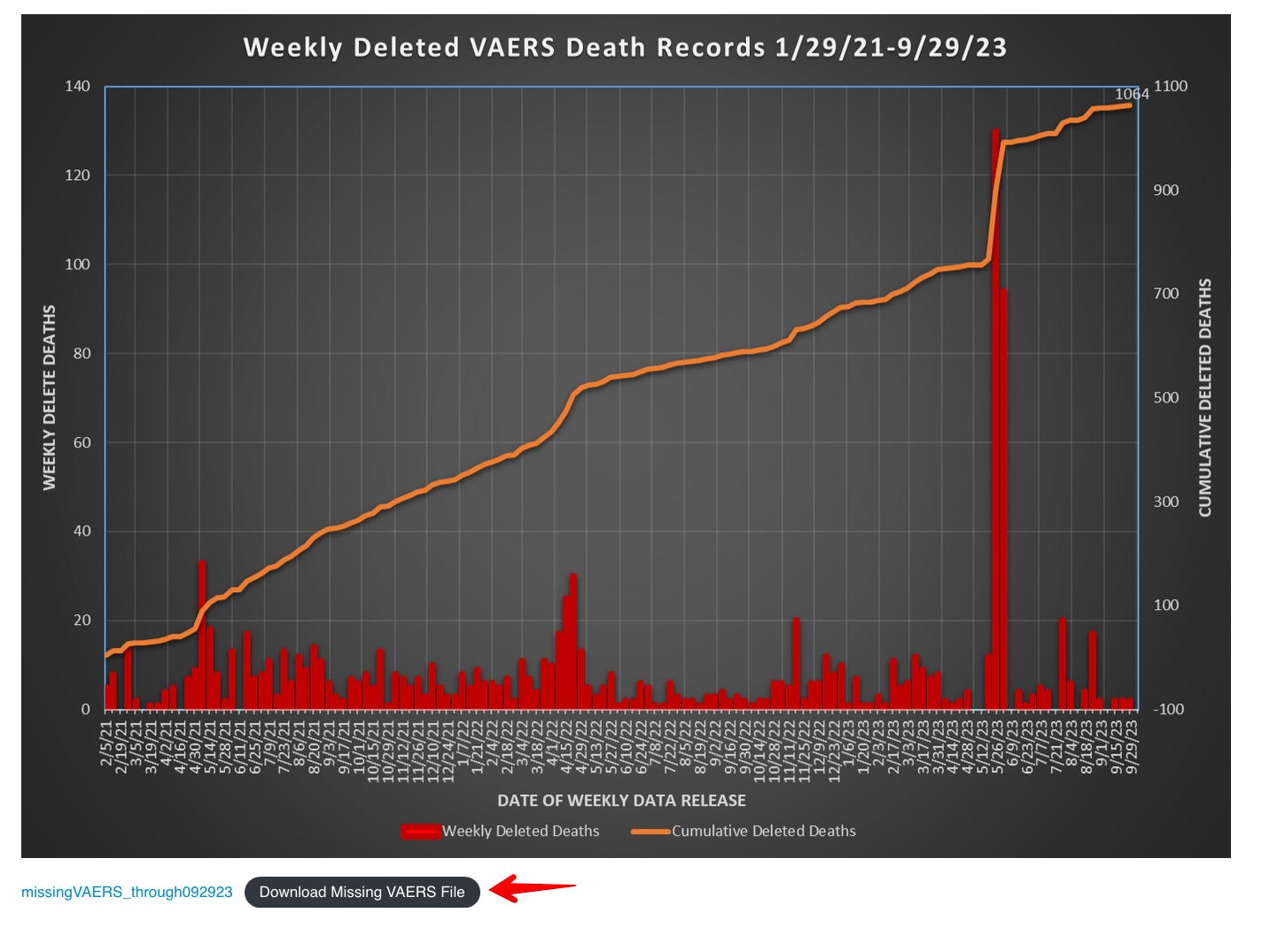
MedAlerts also has a similar feature but it requires a little bit more work on your part.

Why CDC deletes VAERS reports
The process for filing VAERS reports is quite complex.
When you file your first report, you will receive some kind of activation key number.
Some victims had basically filed initial reports 3-4 times via themselves and their physicians. Many victims were getting wrong info from their physicians, because many physicians assumed filing follow-up data was the same process and submitting an initial report. IT IS NOT! There is a method of submitting follow-up data that requires a activation key# being submitted to you first, and a different portal access expressly for this purpose. This observation covers the victims that had since died or became permanently disabled but wanted their public facing initial report to reflect the current status.
You must use this activation key number and also use a different portal to update an older VAERS report you filed.
BTW the VAERS update process is an immense rabbit hole and one which the vaccine pushers probably don’t even know about.
For example:

That’s a pretty odd thing for the Truther to say, given that he doesn’t even understand how the VAERS update process works.
As you can see from the process described above it turns out the reason CDC deletes VAERS reports is not nefarious
However, that is no reason not to do a full investigation of the content of these deleted reports!
Why do deleted VAERS reports matter?
For one thing, it is possible for someone to be hospitalized and submit their first VAERS report, and then the VAERS report is later updated to reflect their death.
In fact, I have already uncovered a few such reports.

The problem is that these do not show up in the CDC WONDER VAERS search as deaths. The outcome of the original report is the only one you can search for.
There is also a second and even more important reason these deleted VAERS reports matter (I am not talking about deaths alone, now I am referring to all deleted reports) - it is very rare that someone files a VAERS follow up if they get better.
Most of the followups are for people who get worse.
So when people study things like myocarditis after the COVID19 vaccine, they should also read6 the writeups for the followup reports if they exist. This is actually a very important subset of data which can be used to analyze whether myocarditis is merely “mild and transient”, and how often it is severe and permanent.
The easiest way to do this analysis7 is for the CDC to publish a mapping between a deleted report and an original report.
And if you have read till this point you can see that the CDC is indeed hiding VAERS death reports from the public.
Will the vaccine pushers ever admit it?
I think at least a few people would be interested in paying for an upgrade if they go one step further and turn those automated transcripts into OutScripts which should be well within the realm of Twitter’s AI capabilities by now given what Grok can already do
While I can write Python code and will download the relevant Twitter spaces if necessary, this automatically eliminates a lot of people who might potentially have the skillset to offer good counterarguments to the debate topic, but lack the technical knowledge to first download the audio recording
Some people might say this is a feature and not a bug. But that doesn’t really make sense for a topic like VAERS (and now v-safe) where almost no one has spent the time to do a really rigorous analysis of all the text writeups.
And even if they had, we now have LLMs which can help solve many problems we previously couldn’t. So I am not sure if people on both sides of the debate even know all the so-called “talking points”.
The additional time is to figure out if he needs the assist, or if Henjin just interjected before Jeff Morris could reply. I cannot blame Prof Morris for the latter obviously.
I wish the person who maintains the website had made this deletions list more prominent and easier to find!
We can now do this with LLMs too, and I have added it to my list of things to analyze in the future.
Within the limitations of the current system and without needing to wait for the entire workflow to be overhauled. While I have implemented a system to automate the mapping between deleted and original reports, it does not have a 100% success rate, and also suffers from occasional false positives.
Vaccine pharmacovigilance is purposefully 3rd rate. If vax manufacturers actually had liability, that might change (though if they still had government agencies recommending their products, I still think they would lie).
The context of my tweet was you were repeatedly asking Morris to answer your unanswered question. But a few days ago I had asked you a question about the same dataset which you still hadn't answered, and I even reposted it on Twitter after you asked me to post it on Twitter and tag Morris, but I forgot to tag Morris the first time so I now posted it again in a thread where Morris was tagged.
I don't think your characterization of Morris as the reply guy under "tweets from high follower accounts" is accurate. He is known for his patience in writing thoughtful replies to accounts with a low number of followers. I think I had single-digit followers when he patiently showed me plots of the English data for mortality by vaccination status which made me realize the misclassification hypothesis presented by Fenton and Neil might have been wrong.
Welcome the Eagle does some good work, but I wonder if some VAERS reports are fabricated as part of some anti-vaccine psyop campaign? The management of VAERS was outsourced to General Dynamics IT in 2020, but it's the same company that was contracted by the Pentagon to run an anti-vaccine psyop campaign on social media: https://welcometheeagle.substack.com/p/general-dynamics-was-contracted-by.