15+ things to remember while doing v-safe free text analysis
If you read nothing else, make sure to read the points 14-16

Please note: there is an important update to this article which affects points 9-11.
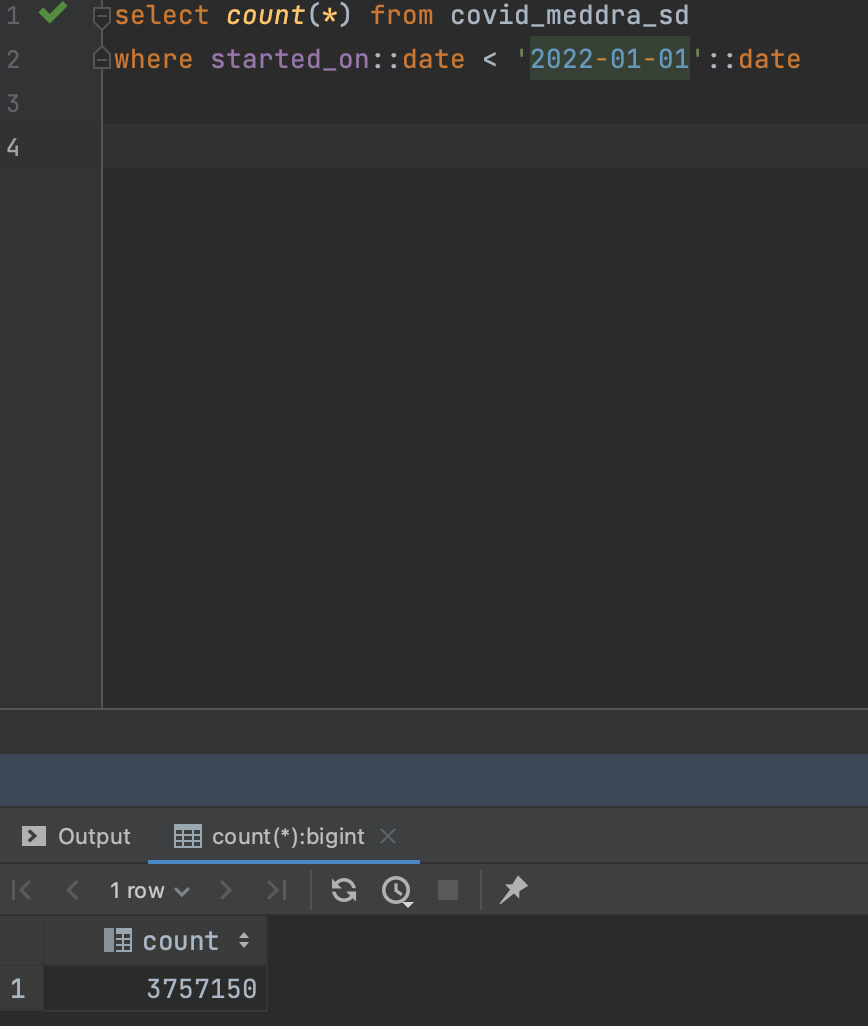
The 5GB "Consolidated Health Checkin" CSV file did have all the 140+ million entries, but I ran into some error when I first imported it into my local DB and it only imported about 65 million entries. Based on that, I wrongly concluded that all the checkin entries were not published by the CDC. In case you are not yet familiar with the story, CDC released the first batch of v-safe free text entries to comply with a FOIA request.
I am writing this article to provide an overview of the data format and also provide a sort of refresher on some past v-safe analysis I have done.
1 The free text was not included in the statistical analysis plan published by the CDC in its v-safe protocol v4
These are the release dates for the v-safe protocols:
v1: 19 Nov 2020
v2: 28 Jan 2021
v3: 20 May 2021
v4: 10 Mar 2022
This is the (Statistical) Analysis Plan for v4:

Notice that there is no mention of any kind of analysis of free text entries, even though there were already over 3 million free text entries providing SYMPTOM DESCRIPTION submitted to v-safe by end of 2021.
The symptom description free text field only applies for injuries which continue until Day 28, as you will see later in the article. In other words, it is quite likely these were not “transient” health issues.
I will also be describing this SYMTPTOM DESCRIPTION field in a little more detail later in the article.
In other words, even while everyone is asking how the CDC could have missed vaccine injuries, no one (especially in the medical establishment) is pointing out that the CDC did not even mention free text entries in its Statistical Analysis Plan.
So people trying to figure out some kind of “gotcha” in these v-safe free text entries which will implicate the CDC should read this old joke1:
A guy rides his motorcycle through the border from Spain to France every week carrying two bags of sand. The border guard searched the bags every time, but never found anything, so he had to let him through. The guard has his last day at work before retiring and the guy comes to the border again, carrying his two bags of sand. The guard says "look, man, it's my last day, I'm not going to bust you. You're clearly smuggling something across the border all this time but we never find anything, what is it.". The guy says "I'm smuggling motorcycles"2 The CDC never did any text mining on the free text data
Obviously, because no one asked them to do it, the CDC did not do any kind of text mining or text analytics on the v-safe free text data.
CDC's v-safe text mining is laughable

This is Part 6 of my Case for Vaccine Data Science series. I was reading a paper about CDC’s v-safe free-text-response analysis, and it is just laughable. First, remember that all the “solicited” responses were just check-the-box fields for known, benign vaccination side-effects and any other adverse reaction was only captured by the free text responses …
3 As of 2024, CDC has published exactly ONE paper which has provided sample v-safe free text entries
Almost no one knew what the v-safe free text entries looked like before the recent data release.
This is because the CDC published exactly ONE paper which provided some sample free text entries.
Peer Reviewed Lancet paper highlights CDC's v-safe text mining failures

Summary: A CDC paper published in August 2022 is the only one (I know of) which published sample verbatim free-text responses from v-safe The paper tries to filter free text responses related to menstruation, and to further classify them on different dimensions like severity etc. using a pretrained Machine Learning classifier
4 The data dictionary provides explanations of different fields
You are going to need to download the data dictionary since it provides an explanation of the different fields provided in the different CSV files.

To summarize:
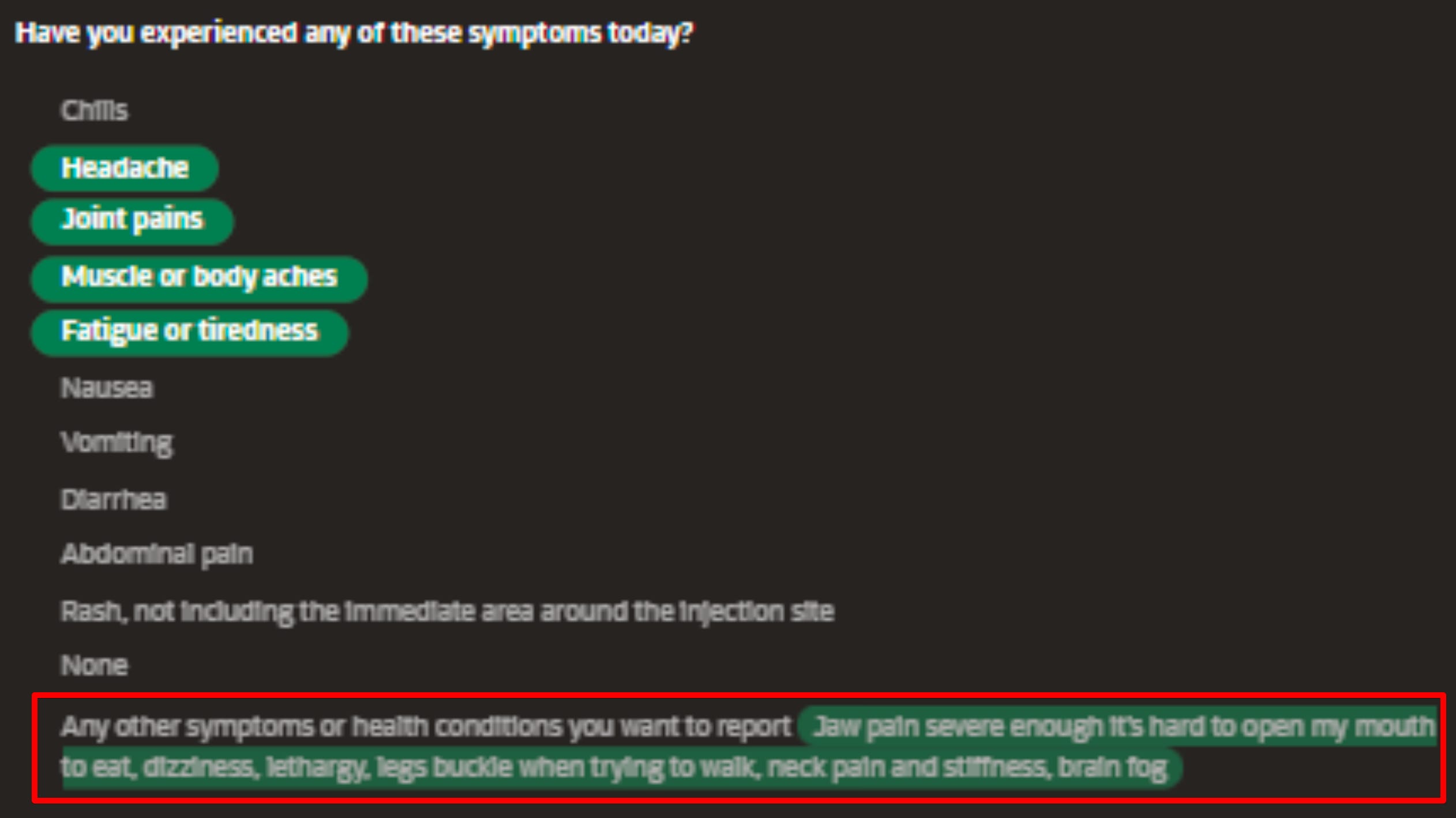
HCVO = HEALTHCARE_VISITS_OTHER (free text field when user mentions they had to go for a healthcare visit)
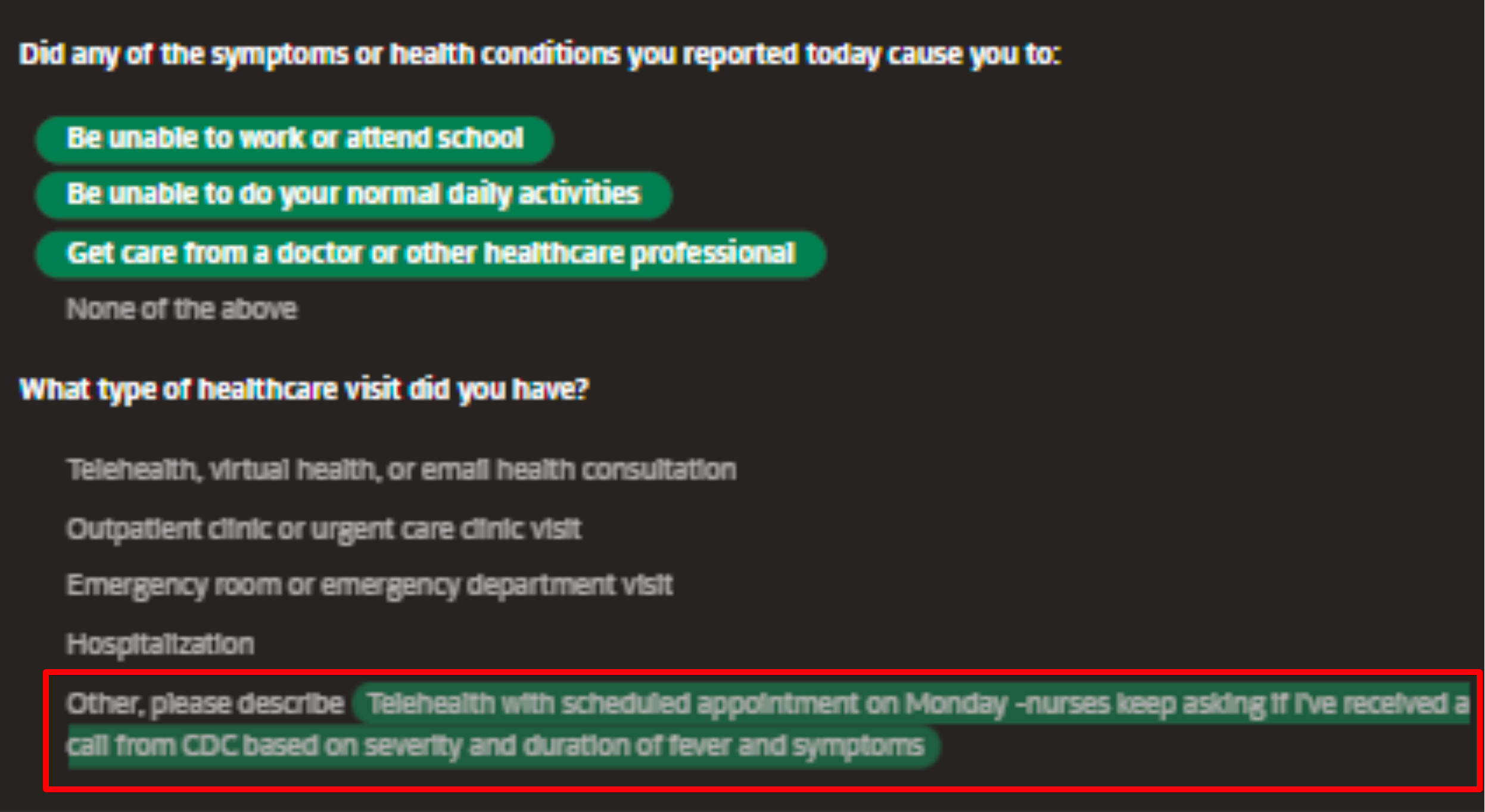
SD = SYMPTOMS_DESCRIPTION (free text field when user mentions they are feeling sick, and the app asks them to describe their symptoms)

SRO = SYSTEMIC_REACTION_OTHER (free text field to capture something other than the solicited symptoms)
5 The v-safe Data Dictionary has a field called DateCoded
You see that all the three types of free text entries have a field called DateCoded, which is the “Date the record was initially coded”

In other words, someone did manually read the free text entry and converted it into a MedDRA code where possible.
6 The earliest DateCoded is only in October 2022
When you run some queries on the data that has been provided, you will notice that the earliest DateCoded is only in October 2022.

This brings up a question - if the free text entries were not coded until October 2022, then how could the CDC be sure that the v-safe data was not showing any danger signals?
On the other hand, if for some reason that date is simply a reflection of when the data was added into the database, this means the actual date these entries were coded were much earlier and close to the date of survey submission. In that case, where are all the publications which should have mapped2 the free text entries for the non-solicited symptoms mentioned at the end of protocol v4?

7 It is possible to construct a timeline view for each v-safe registrant once all the data is available…
v-safe checkins are on prespecified dates with respect to the date of vaccination.

This means you should be able to construct a timeline view of how the adverse reaction progressed over time - did the health condition get better, or did it get worse?
8 Without the full timeline, you will not know if the v-safe participant recovered
This also means that if you do not have a full timeline view, you will not know if the v-safe participant recovered.
In other words, they could have had some adverse reaction which happened immediately after vaccination, and then it got better over time3.
You will be able to do a complete analysis for a given participant only if you have all the surveys that they filled out.
9 The complete timeline information has not yet been published for any registrant
The Consolidated Health Checkins ZIP file consists of all the Health Checkin files which have been provided till date.
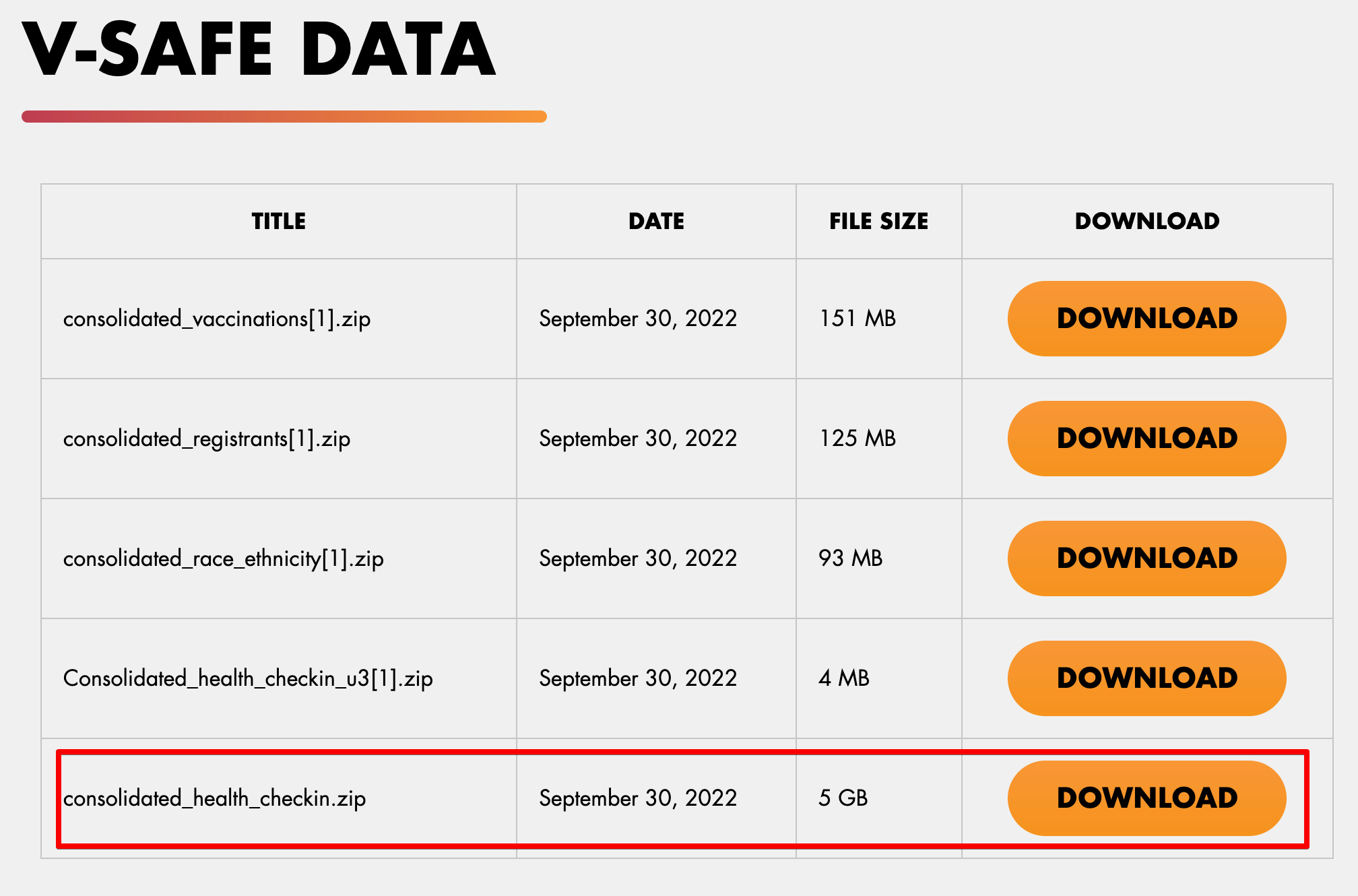
And this is the full list of survey_static_id provided in the Health Checkin files for now.

While this is the full list of possible survey_static_ids

As you can see, there are 210 possible values from survey_static_id, and the health checkins provided so far have only given us the information for 13 of them.
So this means we cannot come to any strong conclusions about the v-safe participants whose data has been published till date.
In fact, it would be a good idea to expect that the CDC now has an incentive to be adversarial about this FOIA and release intentionally misleading incomplete data which leads to wrong conclusions (because the analyst does not have the full picture about any given participant yet).
After all, each time the CDC is able to refute a v-safe analysis by publishing additional data, it not only makes the CDC look like they are actually on top of things, it also makes v-safe analysts look like they do not know what they are doing.10 v-safe asked the participant if they believed the vaccine caused their injury…
In the sample v-safe data provided by Aaron Siri, you see that the app specifically asks the v-safe participant: “Do you believe your/their health problems might be related to your/their COVID-19 vaccination?“

11 .. and that field has not yet been published
But this field has not yet been published in any of the files.
I think analyzing this field is eventually going to be quite revealing.
For example, in the sample v-safe data that Aaron Siri provided on his Substack, the participant answered “No” in their 42nd day check-in.

And then changed it to Yes in their 3 month check-in.

While I don’t know what prompted her to change the answer, this does show that the people who enrolled in v-safe were vaccine enthusiasts and they were not eager to blame the vaccine (for their injury) at the first possible chance.
12 The VSAFE_MedDRA_SRO_prelim_data_04102023 ZIP files are mostly redundant
This is just a bit of a housekeeping note, but there are two files which are related to “V-SAFE FREE-TEXT RESPONSES CONVERTED TO MEDDRA CODES BY CDC CONTRACTOR“
If you unzip these ZIP files, you will see both of them have three CSV files inside corresponding to SD, SRO and HCVO.
The one on the top is more up-to-date and also nearly a complete superset of the ZIP file below. So you can just use the top one for your analysis and ignore the bottom ZIP file.

13 You can map the Consolidated Health Checkins data to the v-safe app screenshots
At some point, you will probably want to take a look at a few v-safe screenshots so you can map the Health Checkin information to the various fields used in the app, and also see if all the data has been published.
The sample data provided by Aaron Siri shows, for example, that the field which answers the question: “Do you believe your/their health problems might be related to your/their COVID-19 vaccination?“ has not yet been published (as I have already mentioned before)
14 The RESPONSE_ID field is missing in Interim Release 1
You will notice that all the CSV files for SD, SRO and HCVO have a field called “RESPONSE_ID” - it is a “Unique Participant Survey ID“
Here are some example ResponseIDs for the SYMPTOM_DESCRIPTION file:

As you can see, these are just autogenerated large numbers, and do not contain any Personally Identifiying Information (PII).
Also notice that you will be able to easily infer the number of days post vaccination from the ResponseID.But the RESPONSE_ID has not been provided in Interim Release 1, and it looks like a pretty big omission to me:

I will explain why in the next 2 points.
15 The SYMPTOMS_DESCRIPTION field only appears on Day 14 post vaccination…
The Highwire article about the release of the v-safe data mentions the following (emphasis mine):
Indeed, District Court Judge Matthew Kacsmaryk’s ruling is a huge win for transparency, and yesterday’s first production of at 390,000 entries outlining what users experienced in the first two days of receiving the “vaccine” is telling.
Unless I made some kind of basic error on my end, I don’t think it is accurate to say that ALL the first production of 390K entries outline what users experienced in the first two days.
For example, there are over 40K entries where the SYMPTOM_DESCRIPTION is not empty.

But this field is only shown in the survey on Day 14 at the earliest (you can verify this by looking at all the v-safe app screenshots)
I will point out that the 40K SYMPTOM_DESCRIPTION entries which were provided already have some fairly significant serious conditions.

But since there is no RESPONSE_ID in the Interim Release 1 CSV file, we don’t really have any way to know how soon after the vaccination the specific free text entry was submitted (this corresponds to the ONSET_DAYS field in VAERS)
16 … which means we don’t know the days to symptom onset for ANY of the entries in Interim Release 1
Without access to the ResponseID, we will not be able to4 confirm how soon a given health issue occurred post vaccination.
Given that we also do not have all the CheckIn information (so we can construct the complete timeline), this means we don’t know when the problem started, and whether it actually resolved.
When you combine these two things, it is possible that people do some v-safe free text analysis which would later be disproven by the CDC.
So I would urge people to be very cautious about publishing the results of their findings until the ResponseIDs are provided in the datasets.
Also, in case you think I am wrong about the importance of the RESPONSE_ID or if you have figured out some kind of workaround to infer it, please let me know in the comments below.
I am not suggesting that there won’t be any gotchas at all. I am simply pointing out that no one who was “peer reviewing” the v-safe publications raised this objection AT THAT POINT IN TIME, and the CDC is probably going to say they were not “required” to do this free text analysis because no one asked them to do it!
For example, in my article about CDC’s v-safe text mining, I point out that the CDC did use some string regular expressions to try and do this mapping for the solicited symptoms.
Why didn’t they do the same kind of mapping for the “Adverse Events of special interest” mentioned on the last page of v-safe protocol v4 and publish a paper on that topic till date?
I have seen some theories suggesting that the people who have immediate adverse reactions are more prone to severe injuries after a few months. But in theory, given that v-safe has a pretty long followup schedule of 12 months, that should be captured in the data. In other words, I think people who felt temporarily better but got worse after a few months, would be quite likely to open the v-safe app and report any new health concerns.
I suppose there will be some way to write some code to infer this by perhaps using some kind of a process of elimination. But that misses the bigger point - there is really no reason this information should be omitted from the FOIA response.
A heartfelt thank you for your hard work.
Great article Aravind, I might add a couple more visuals on my soon to be published dashboard because of this article. There were at least ~446 symptoms of "death" not including the other flavors like sudden death, foetal death, brain death, etc..
One over arching sentiment not generally mentioned or elaborated upon here is that vsafe was not designed to be auto crosswalked into VAERS. Since only ~36K reports in VAERS show an association with Vsafe we can effectively say these are two independent sets of victims, VAERS vs Vsafe. If Vsafe had not been created, how many more reports might have been submitted to VAERS? In my opinion Vsafe was created to run interference on VAERS. Vaccines are highly toxic doggy doo-doo mixed in with some less toxic doo-doo to kill you slowly and/or shorten you life IMO.
Work in progress:
https://public.tableau.com/app/profile/alberto.benavidez/viz/Vsafe/Dashboard