Identifying REPORTER field from the writeups of serious VAERS reports
And a comparison between US and foreign reports

People may not know this, but VAERS actually collects a lot of information about the person who files the report.

But they don’t publish the information collected within the checkboxes. (To the best of my knowledge they don’t even provide aggregate information about the Reporter checkbox, if I am wrong please leave a comment).

In a previous article, I mentioned that a quantitative analysis comparing the US and foreign writeups leads to some very interesting findings.
The reporter field is one of them. The quality of the foreign writeups is so high, you can identify the reporter for over 90% of the reports by writing some code.
A quick note about the datasets I used: I only considered serious VAERS reports where one of the following is true: DIED, L_THREAT, HOSPITAL, DISABLE. For the US reports, I used the CSV files I downloaded around March 2023. For the foreign reports, I used the last known “good” version which had all the EU writeups. (I got the CSV from a fellow VAERS analyst).
Note: I am only publishing the first 10000 rows of analysis. It is a large enough sample size to make my case, and saves me some compute time/storage space.
Healthcare professionals
I use the spaCy DependencyMatcher to identify the reporter.

I have a list of keywords which I use to identify healthcare professionals.
hcp_list = ["physician", "nurse", "pharmacist", "hcp", "professional", "regulatory"]The keyword “regulatory” refers to reports which are downloaded from the regulatory authority or regulatory agency. I make the assumption that these are actually filled by healthcare professionals. If I am wrong, please let me know why in the comments.

First person vs third person
I have also added two columns into my dataset to indicate first person and third person reports. This is based on checking to see if there are 2 or more times a first-person (I, me, my) or third-person (patient, he, him, she, her) keyword appears in the writeup.

This is a pretty crude heuristic, but for the most part it seems to work quite well1.
Entity Score
Like in my previous analysis, I use an off-the-shelf Machine Learning model to calculate the medical jargon mentioned in the writeup.

I also provide the list of entities identified in the writeup in the column called ENTITY_LIST
Reporter Count
Here is the list of reporter counts for the foreign reports. Only 730 = 7.3% of times the reporter is unidentified. On top of that, the consumer2 is only 22.76% of the reports. The rest of them combine to nearly 70% - in other words, nearly 70% of the serious foreign reports are made by healthcare professionals.
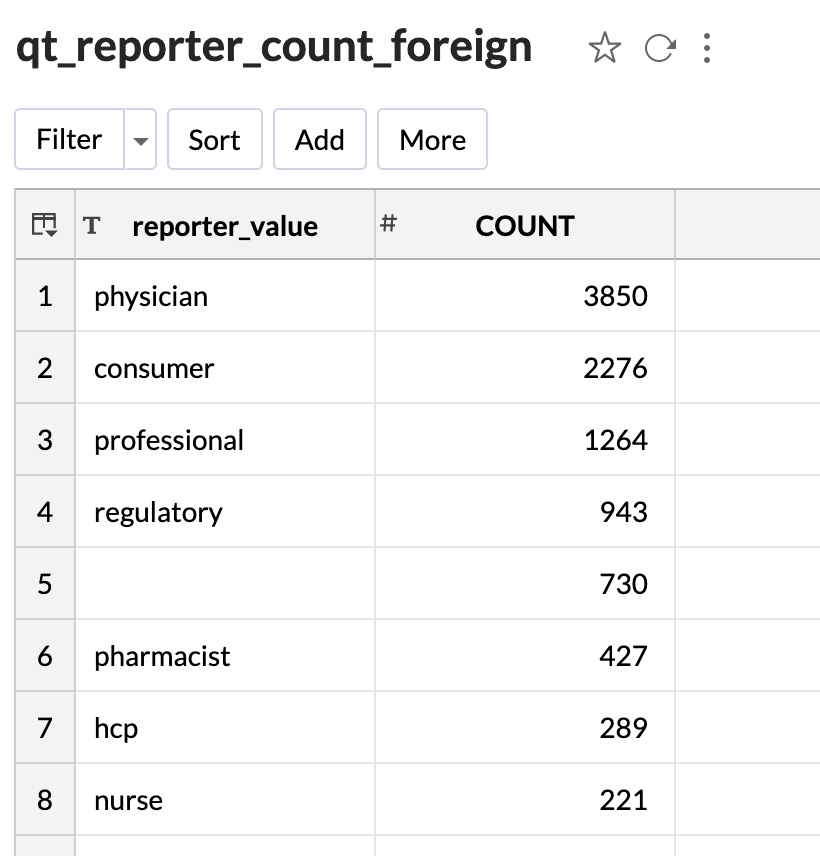
Now compare this with the US reports. We cannot even identify the reporter for 92% of the reports. The consumer makes up nearly 5% of the reports. So only about 3% are identifiable as reports made by healthcare professionals.

First person vs Third Person comparison
Please note that it is possible for a report to be both first-person and third-person because even if the reporter is a healthcare professional, they sometimes quote the first-person report verbatim. So you see both third-person and first-person keywords in the same report.
Here is the count for foreign reports. As you can see, 96% of reports are third-person only - meaning they had only keywords which referred to the patient in third person. These are very likely to be reports from healthcare professionals.

Let us compare the average entity scores for each group for the foreign reports.
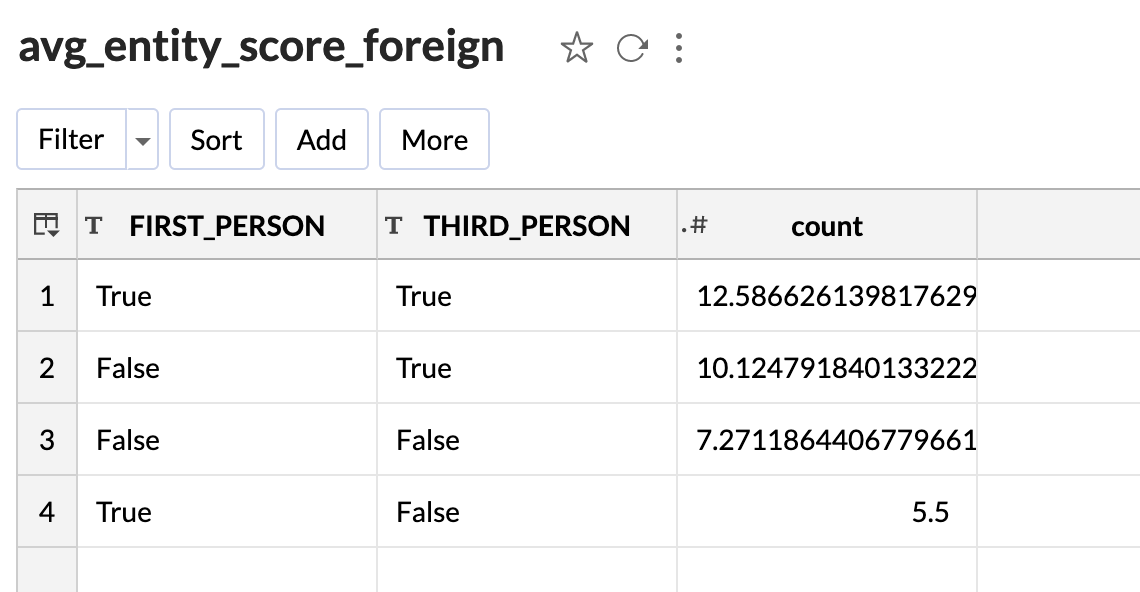
As you can see, the lowest entity score average is still over 5, and it is for first-person reports.
Here is the report for US:

And here is the average entity score for each group.

As you can see, we cannot identify first-person or third-person in nearly half the US reports (48.4%), and they also have a much lower average entity score.
Summary
It is very clear even from reading the writeups that the foreign VAERS reports are qualitatively much better than the US VAERS reports if you want to do text analysis3.
In this article I have tried to quantify this.
And you can also combine these heuristics to create some “meta-heuristics” which map a report to the four checkboxes we see in the Reporter field. And we can also use ML to improve these heuristics. This is another example where David Gorski is wrong about VAERS because he does not seem to realize how much data science can help improve VAERS analysis.
If you look at some example reports (you can filter for consumer and click the URL field to read the report on MedAlerts), you can see that usually the word ‘consumer’ often refers to the patient or their caretaker.
I think one explanation for this is that it is much more likely that a non healthcare professional will file a VAERS report in the US. I think foreign nationals are a lot more likely to first go through their own vaccine injury reporting system.