
Analyzing text length for v-safe entries by type
Analyzing text length for v-safe entries by type
While there does seem to be a hard limit of 250 characters for SD and HCVO, there isn't any hard limit for SRO

Reminder:
SD = SYMPTOMS_DESCRIPTION
HCVO = HEALTHCARE_VISITS_OTHER
SRO = SYSTEMIC_REACTION_OTHER
This is a short article to point out that the v-safe free text entries are not all less than 250 characters.
I saw this limit mentioned in an
article:Here is the snippet (emphasis mine):
(For what it’s worth, VAERS has two advantages over v-safe. First, a user can submit an unlimited amount of information to VAERS about an adverse health impact. That is not true of v-safe which limits its free-text fields, where users can report symptoms, to 250 characters. Second, pursuant to federal law, certain deidentified information submitted to VAERS is supposed to be promptly made public, and while this does not always happen, there is no legal obligation for CDC to promptly make public the v-safe data.)
But in reality, the 250 character limit only applies to the SYMPTOMS_DESCRIPTION and HEALTHCARE_VISITS_OTHER fields, while the SYSTEMIC_REACTION_OTHER actually allows much larger free text entries.
Here is a SQL query I used to compare these three CSV files:
select length(systemic_reaction_other), count(*), min(systemic_reaction_other), max(systemic_reaction_other) from "InterimRelease1"
group by length(systemic_reaction_other)
order by length(systemic_reaction_other)
This is what the results of this query look like1:

I also ran a similar query for the other two types of free text fields and then used these datasets as the basis for the charts below.
Free text entry length (chars) vs Number of such entries
I plotted the count of entries as a function of entry length (in characters) for all the three types, for values of length > 150 characters.
Here is what the chart looks like for these three datasets
SYMPTOMS_DESCRIPTION:
Notice the peak towards 250 characters, and then the precipitous dropoff.

This suggests the app user interface had some hard restriction on the number of characters that the user could type into the free text field, and you see people trying to squeeze in as much information as possible before they hit that limit.
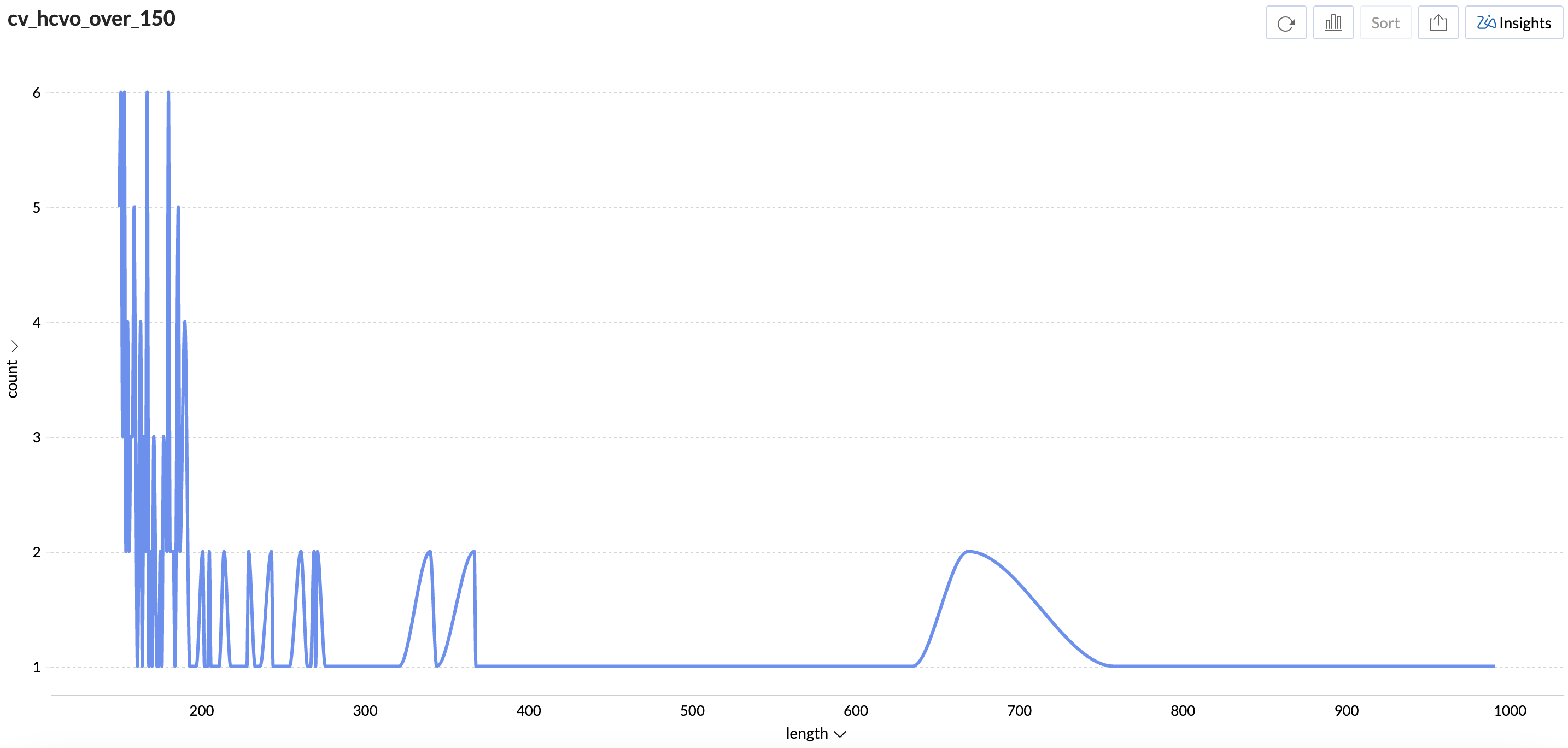
HEALTHCARE_VISITS_OTHER:
This chart looks very different with very few entries over 150 characters. This makes sense because people are not usually filling out a lot of details in this particular field (they use the SRO and SD for that). While there are some pretty long entries, the total number of such entries is just a handful.
SYSTEMIC_REACTION_OTHER:
You can see that this free text field is markedly different from the other two.
First of all you can see that there are many free text entries per length even for free text entry length - in fact you see at least 10 entries each until around the 350 character mark.
And second, you see that as the text length gets larger, the number of entries gradually slopes down, which is what you would generally expect when users are typing without any constraint on the text input length.

When doing text analysis of the v-safe free text entries, it would be a good idea to keep this in mind.
Why does this matter?
The three symptoms files - covid_meddra_sro, covid_meddra_hcvo and covid_meddra_sd - all do the same thing. They “code” the free text entries into MedDRA Preferred Terms and Lower Level terms.
But as the length of a free text entry increases, it means that there is a lot more information provided in them which isn’t captured by just using MedDRA codes.
In fact, this is quite easy to reason about when you consider the many different fields in VAERS which we do not have in v-safe - fields like current illness, history, other medicines, lab data etc.
And you can see that sometimes the v-safe free text entries mention this type of information.
So when we do text mining of the v-safe information, it would be a good idea to consider the length of the free text entry and compare it with the MedDRA codes for it. This would give us a good idea about the information which was provided by the user, but which hasn’t yet been converted into a relational format2.
To put it in another way, using just Preferred Terms and Lower Level Terms3 to describe the free text entries in v-safe is probably ignoring a lot of potentially useful information.
In the next few articles, I will explain how we can extract this information and turn it into a relational format.
The image starts at length = 28 to provide more readable free text entries, but there are entries beginning at 1 character long. The min() and max() functions are only used to show examples and I do not use them in further analysis.
For our purposes, the term “relational” means data which is queryable using SQL
Which is what the CDC has done till date. They have not done any text mining of the free text information to the best of my knowledge.