

Searching across FOIA documents
I built a simple search engine to do this (No direct links, you still need to download the files to your local machine)

My Twitter friend
recently got a request from a follower: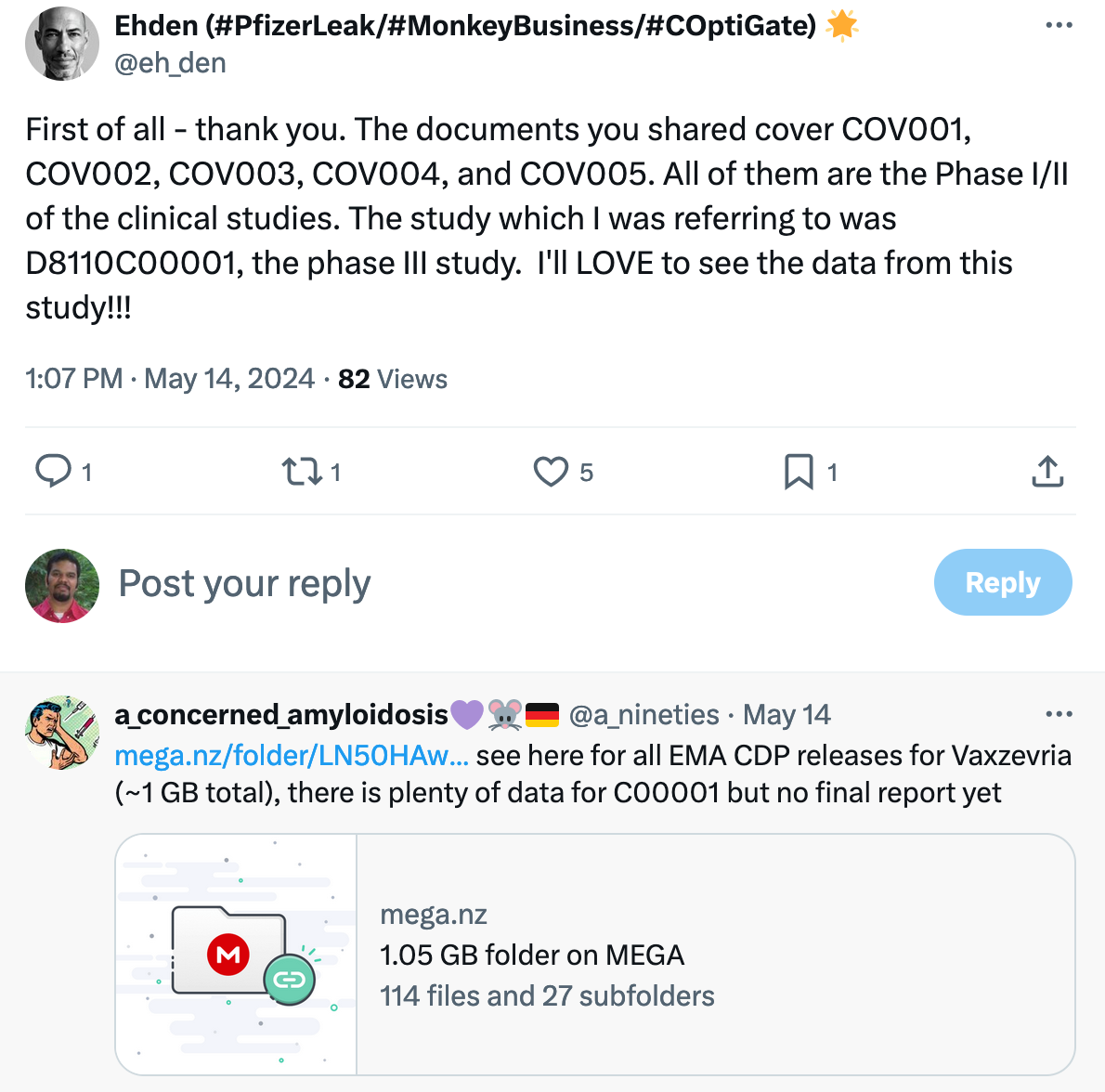
I asked if it would help to build a small search engine for this, and he gave me a link to a post on his Substack with the full list of Mega uploads.
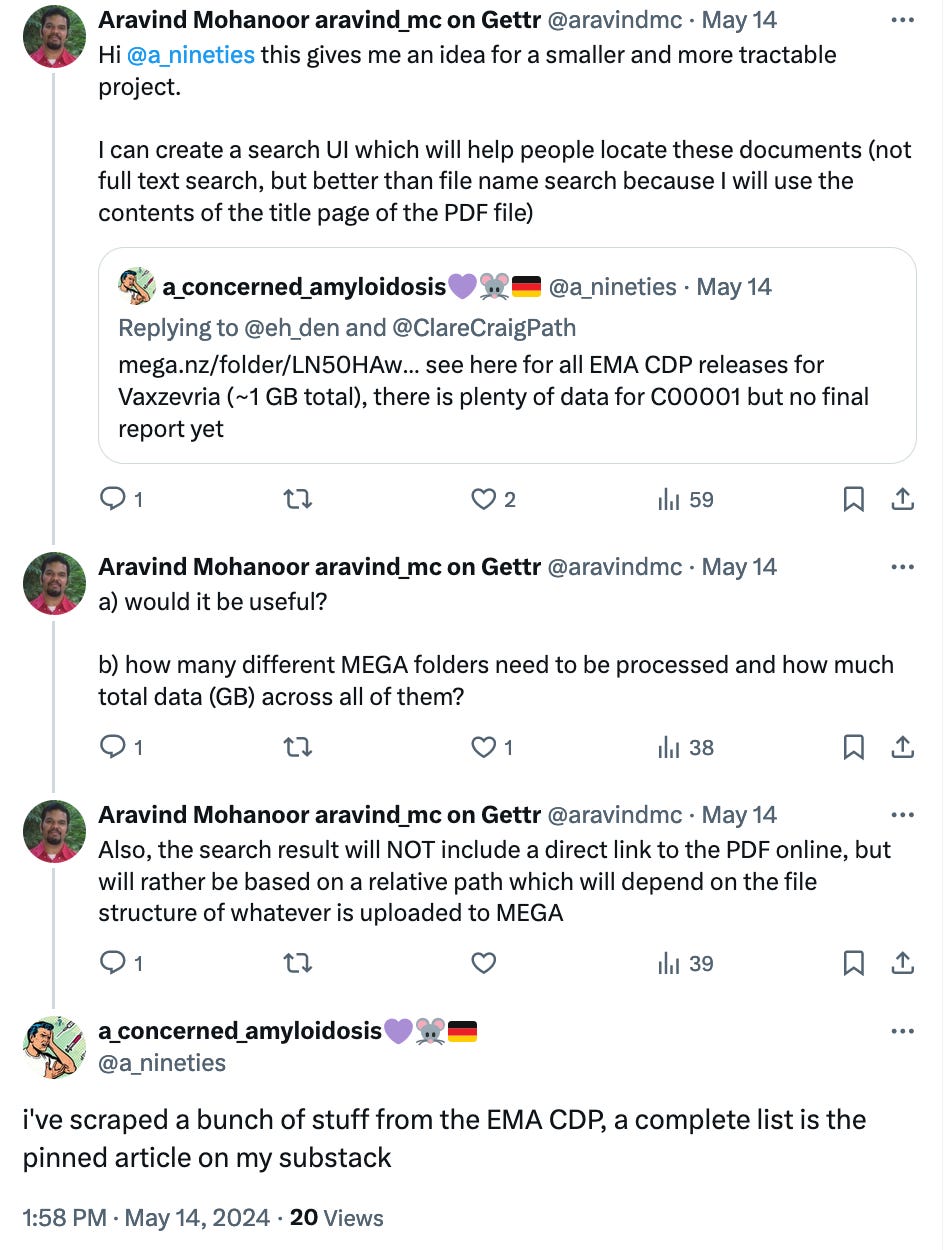
Turns out, it is actually quite simple to build a quick search interface for this using Algolia.
This is what the search engine looks like at the moment, but I will be improving it over time by adding more filters.

How it works
I extracted the text from the first 5 pages1 of each PDF file and constructed a search interface using Algolia. Algolia has a limit of 10K characters per record, so I truncate anything over the first 9500 characters. This is usually plenty for a page, but sometimes the text content in a single page can go over the limit for some PDF files.
The basic idea behind this search is that the first few pages of these documents contain both the title of the document and often also include a table of contents.
Clearly, this is much better than a simple file name search, but not as exhaustive as full text search across entire documents. I wanted to build something which will fit into the Algolia free plan.
Does it work?
So I tested it with the specific document that the person on Twitter was asking for, and got 134 hits. You can see it is also organized by document type.

You need to download the ZIP file from Mega and extract all files to your local machine and then use the search result to identify the PDF filename and the page number.
Would you like to see more PDFs added to this?
If you have any additional FOIA PDF2 documents you would like to add to this search engine, please let me know in the comments.
If it can be done within a reasonable amount of time, I can create a search UI for your documents.
Would you like to see more filters?
Is there any other filter you would like to see on this search engine?
I think I can do simple Named Entity Recognition on the text that I extract and construct more useful filters.
Indexing the entire document, at the rate of about 1 record per PDF page, will require a lot more capacity than what you get with the free tier of Algolia.
For now I only know how to extract text from PDF files. It is also possible to get data from other file types, but that would be a lot more involved and also it might involve parsing the structure in a way that would not make sense for a free text search service like Algolia.
Great initiative !
I had made something similar with the Pfizer documents back in the day ; a good tactic if you want to get rid of the limitations of Algolia is to pre-parse all the files to build a JSON index of the words and their total occurrences in documents - allows to keep a very performant search upon query.
See here if interested :
https://github.com/OpenVaet/openvaet/blob/main/tasks/pfizer_documents/get_documents.pl#L293