Can you improve VAERS analysis by using Natural Language Processing?
New Zealand provides an excellent case study

You will see many people produce dashboards based on VAERS data by using all the information from the three CSV files. Since the narrative text (SYMPTOM_TEXT) field is a string, it usually does not feature in these dashboards and visualizations.
The main reason I created this Substack was because I noticed that almost everyone who was producing these dashboards were almost entirely ignoring the narrative text. Since there is no simple way to make text information “relational” (that is, use it in SQL queries and such), it does make sense that they would ignore it.
This is a big problem, because quite often there is some important information provided in the narrative which is not recorded in the corresponding field.
The best case study for this is actually New Zealand.
One of my very first articles on this website was about using spaCy’s dependency matching to extract age information.
I first created individual data CSV files for each country based on the pattern I discuss in this article
Then I used the following script to analyze the narrative text and add the following pieces of information: DERIVED_AGE and NUMDAYS_BOUND
Note: I haven’t had the time to clean up the script, but you can read it and get an idea of the algorithm I am using for doing it.
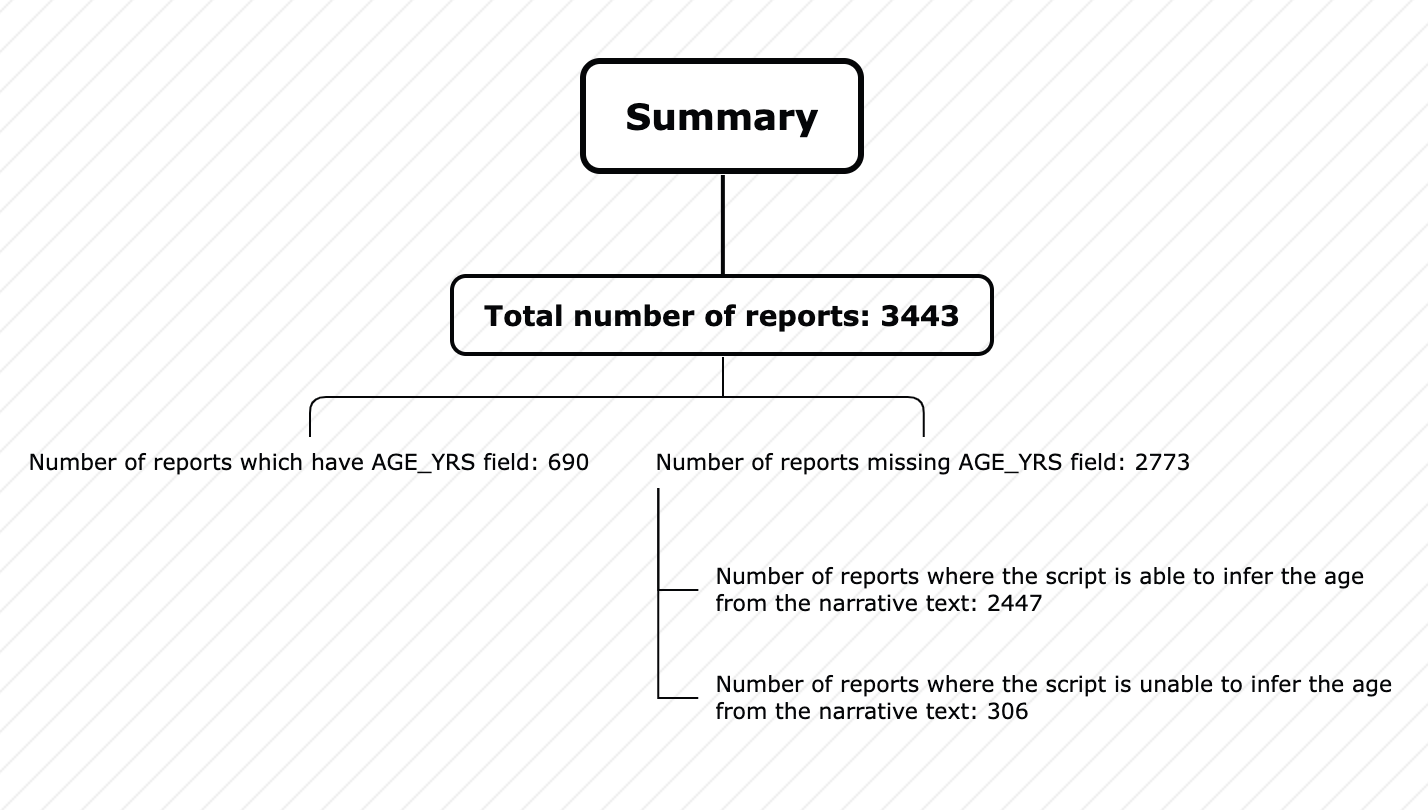
This is the result of the analysis:
Note that there are a total of 3443 rows (on the date this data was downloaded, which was about a month back)

Now filter the dataset to see all rows where AGE_YRS is empty. There are 2753 rows.
Does this mean that 2753/3443 = ~80% of the New Zealand reports do not report the age?
Actually, not really.
The majority of reports do mention the age, but the field AGE_YRS is blank - the most charitable interpretation is that no one processed the information
So what happens if you check the DERIVED_AGE for these reports?
Let us do the following filter:
AGE_YRS is empty and DERIVED_AGE is not empty

There are 2447 such rows, which is actually 2447/2753 = ~89% of all the missing AGE_YRS rows.
The script simply copies the AGE_YRS field into the DERIVED_AGE field where it is available.
So we can see how many DERIVED_AGE rows are empty - these correspond to the cases where the narrative text actually does not provide age information, such as the example below:
“Allergic reaction; This is a spontaneous report received from a contactable other healthcare professional from the Regulatory Authority (Regulatory authority number unknown). A patient of unspecified age and gender received bnt162b2 (COMIRNATY), via an unspecified route of administration on an unspecified date (Batch/Lot number: not reported) as UNKNOWN, SINGLE DOSE for COVID-19 immunisation. The patient's medical history and concomitant medications were not reported. The patient experienced allergic reaction on an unspecified date and was managed appropriately. The outcome of the event was unknown. No follow-up attempts are possible; information about batch/lot number cannot be obtained.“
When you filter for the rows where DERIVED_AGE is empty, you get 306 total rows, which is only about 9% of the total rows, which is a dramatic improvement over the nearly 80% of the rows which are missing if you just used the AGE_YRS field alone.
Here is a summary