

A clarification about VAERS deletions
I am only referring to permanent VAERS IDs

Key takeaways
When I say VAERS deletions are not nefarious, I am only referring to reports which already have a permanent ID and have been published to the public CSV file
It does look like there are also other kinds of data deletions, but those are much harder to prove
I focus on permanent IDs because it means anyone, including the vaccine cheerleaders, can independently verify my work
I am almost 100% certain all deleted permanent-ID-reports have original permanent-ID-reports somewhere in the system. They are sometimes very hard to find because the deleted report is of very low quality
I read this article by Jessica Rose which referred to my previous VAERS deletions post:

I want to clarify that when I say VAERS deletions are not nefarious, I am only referring to permanent VAERS ID numbers.
In fact, to quote the article by Jessica:
Imagine this if you will. A person succumbs to myocarditis a few days after their second Pfizer shot. Said person submits a VAERS report online and receives a temporary VAERS ID. This person is contacted by vetters at CDC and verifies the details of the filing and in turn receives a permanent VAERS ID accessible in the VAERS public data available for download.
Everything I am talking about is after the permanent VAERS ID is assigned, and in fact after it is added into the weekly CSV file which gets published.
There are two reasons why I only discuss deletions of permanent VAERS ID reports:
a) I am not sure how, as an outsider, someone can even prove if partial updates are being deleted
b) I want others to be able to read my article and replicate all my results for themselves by writing code
Said another way, when I refer to a VAERS report as deleted, you should be able to visit the corresponding URL on the MedAlerts Wayback Machine and verify that it has this “Record is removed as of..” blurb at the bottom of the page.

Are these the only types of deletions?
While I cannot prove it, I am aware of the other different types of data deletions.
In their VAERS audit, the React19 team proved that only 61% of the audited reports were fully and correctly published, and there seems to be at least three different ways that the full reports do not end up in public facing VAERS as you can see below.

Someone also told me on Twitter that the information they submitted to VAERS was not fully updated even though they submitted a lot of information.
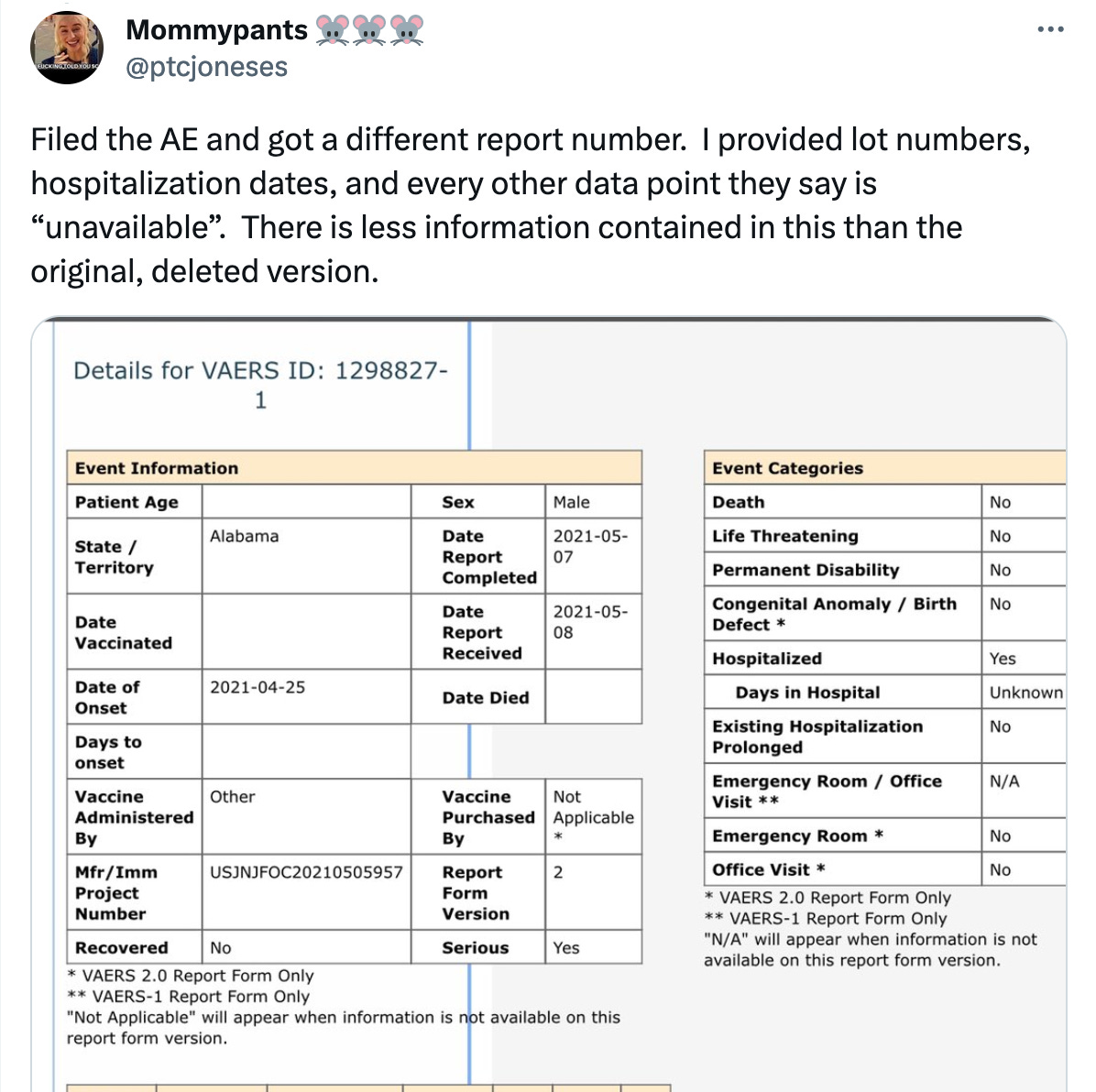
And of course, Jessica also wrote about the business rules for doing updates, and asks a lot of important questions:
I often call this ‘the front-end data’. Their VAERS report likely contains the MedDRA code ‘Myocariditis’ in one of their SYMPTOM fields. Now, imagine that a few weeks later, said person dies. Their GP attempts to update the person’s VAERS ID to indicate that the person succumbed to death. Here’s where it gets muddy.
How does this work? Does the GP call the CDC? Does the GP file the report using the online system? If so, does this ‘Secondary Report’ get merged with the ‘Primary Report’ based on variable field matches? Does this ‘Secondary Report’ get destroyed? According to the contract, the follow-up or updates never make it to the front-end data set.
Read the following found on page 21 and 22 and see if you can figure out if such a death follow-up report would be deemed an ‘Exact Duplicate Report’ or a ‘Redundant Report’, or neither.
So there may be all kinds of deletions happening to the information before it even gets into the VAERS CSV files, and I agree with Liz Willner from OpenVAERS when she points out that VAERS is actually two sets of books.
But I am only referring to the public facing permanent VAERS ID information.
Why does this matter?
In one of my previous articles I wrote about how the CDC is lying about not having deleted any death reports.

But I was using only public facing data to write that article, which means it is verifiable by anyone, including the vaccine cheerleaders.
In other words, I don’t want to make arguments which cannot be independently verified.
Am I certain that all the deletions are just followups?
This leads me to the next question.
Suppose we are discussing only permanent VAERS IDs which have been published in the CSV files once, and then removed from the CSV file on a future date.
Am I certain all the deletions are just followups?
No, I cannot be 100% sure. But I am 99% sure.
Here is an example.
In a previous article, Albert Benavides (thanks for the example!) asked the following question:
Did you find a match for deleted death report ID# 1631954? It was one of the recent JJ mass purge reports?
I will walk the readers through the process of finding the match.
Here is the VAERS report on MedAlerts
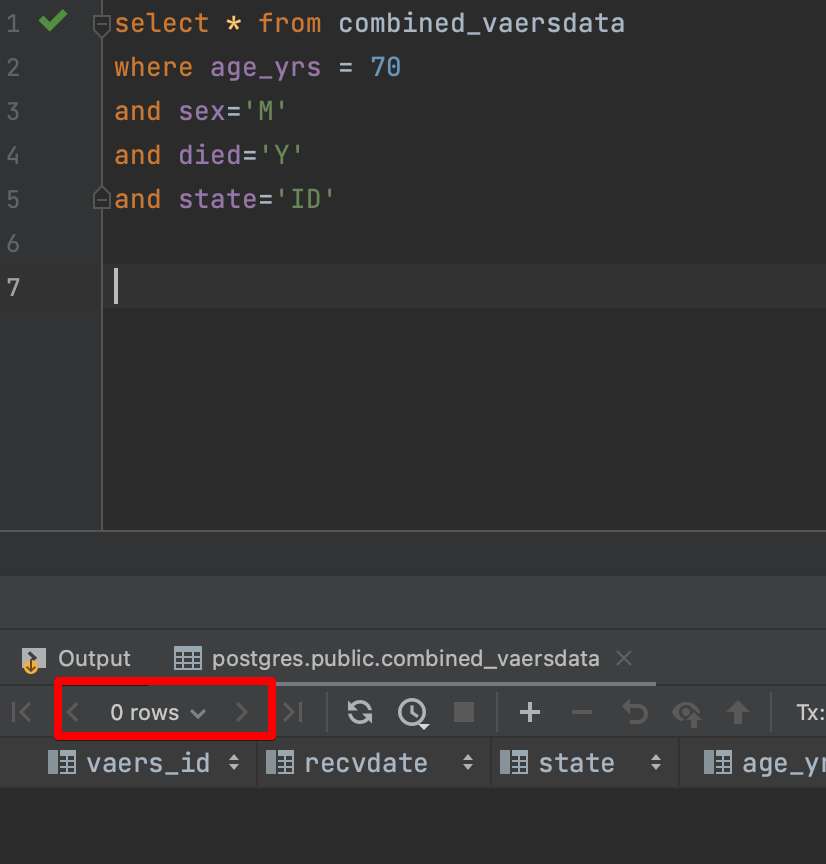
We know the following by reading the report: it was a 70 year old male from Idaho. We know the patient died, but not the date. We also know it was due to the JNJ vaccine.
My first query will try and match ALL the information we already have to find if there are any matches.
There are zero matches.
But we need to remember this: not all fields might have been filled out for the original report
A quick aside: In fact, this is the basis for my indirect claim that a large majority of followup reports become more complete, more serious or more conclusive. If I cannot find the original report using all the information I have seen in the followup report, as in the case above, it automatically implies that the followup report is more complete than the original
So let us allow null values for some of these, keeping in mind that we expect that the death was still recorded
But this gives us 478 - too many matches

So let us make a reasonable assumption that the writeup must have mentioned the vaccine name (ad26.cov2.s)
This reduces the results to 160. This is reasonable, but still way too many to read manually.
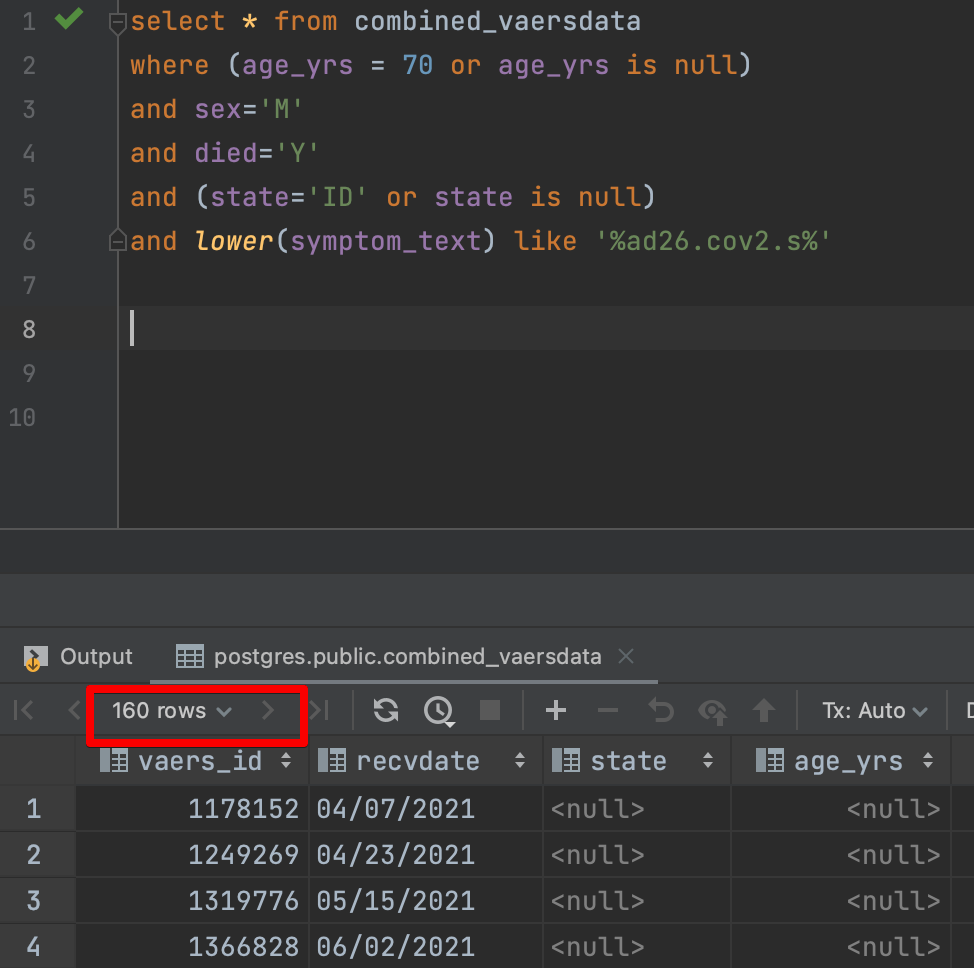
Given that we already know the RECVDATE of the deleted report, we can make another reasonable assumption and only search for reports with earlier RECVDATE values.
Now we are left with only 17 rows to search.

Now comes the part where I use a bit of intuition1.
In reading the deleted report, I notice the following phrase:
“It was reported that patient was pretty healthy“
You cannot expect the same sentence or even the same phrase in the original report, but you can expect a single word, and the word “healthy” is reasonably uncommon in a VAERS report.
These are the kind of clues which you can use for doing a text search, but it will be very challenging to automate this process of figuring out these uncommon terms we can use for the search query. Even to verify this, you will still need to read the report2 (and sometimes it will still be hard to tell as you will see).
In this case, we had already narrowed things down so much that it was pretty easy to filter
So I added the check for the word “healthy” and got exactly one result

If you look up the MedAlerts page for the original VAERS report you can see that
a) you cannot tell for certain if the deleted report is a followup for this one
b) but you cannot be certain that it is not, either

Why?
Because nothing in the original report contradicts anything in the followup report.
And the reason for this is that there is too little information in the deleted report.
That is why I refer to these as “low quality” deletions in my recent article about the Janssen deletions3:
As you can see from this example deleted report, the recent deletions are mostly very low quality reports because they don’t provide enough information to enable us to write an algorithm to identify the original report. As a result, mapping the deletions to their originals is likely to end up as a very costly effort without providing much insight.

In my opinion, it is hard to develop an intuition for what to look for unless you have spent at least a few weeks parsing the VAERS writeups. This is why proper text analysis of VAERS writeups is so important to get the full picture.
I do think a spaCy Machine Learning model dedicated to VAERS can help accelerate this deduping process, but creating the model itself will require considerable time and effort
There is also another reason I believe this. I think the CDC is well aware that many independent analysts are now monitoring VAERS quite closely, so I don’t expect them to do something this blatantly stupid. I personally think they are pretty sure it is quite safe to delete these Janssen reports.
Very well done, Aravind! Your investigations have effectively resolved the matter of deleted reports, it seems to me. I think part of the problem, as illustrated in the case you highlight, is that VAERS is going beyond its protocol and accepting weak/incomplete reports from manufacturers that it wouldn't accept from others. That is, the manufacturers pick up social media mentions of adverse effects and take these non-identifiable cases and report them to VAERS. So both the manufacturers and VAERS are being too liberal in their reporting.
These kinds of cases also show the curious phenomenon of medical professionals spending the time to post adverse effects of non-identifiable cases on social media, yet apparently not spending the time (instead) to report to VAERS directly. That seems to be evidence that those professionals may be violating the law. Of course, most medical professionals ignore adverse effects and even when they recognize them do not report to VAERS, despite their legal obligations. But those professionals who post such information on social media but don't report to VAERS seem to be clearly guilty. There are many culprits in adverse effect underreporting.